|
今天这篇我们来扩展一下,来看看它的另类用法。

第二参数为数组时会怎样? 将REGEXP函数的第二参数用常量数组看看会怎样: =REGEXP(A1,{"[^一-龟]+","[一-龟]+"}) 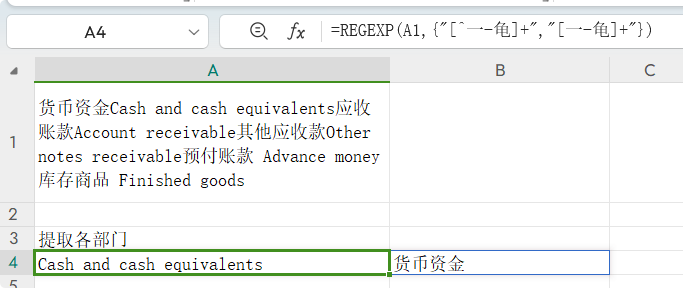
如果不理解什么是常量数组,请看这篇文章扫盲: [color=inherit !important]大括号,用处大,{1,0} {1;0}中间分号逗号是干啥?​mp.weixin.qq.com/s?__biz=MzIxOTYwNTA1OQ==&mid=2247491494&idx=1&sn=4c95209611b0e60ad1d656917c7b4e7f&chksm=97d9ee8aa0ae679c143eef0a1166c4651a0c5c44b0f035825b337aaa1bc7815aa9ca7dcf4149&scene=21#wechat_redirect
在第一篇文章中介绍过, 用=REGEXP(A1,"[^一-龟]+"})提取英文, 用=REGEXP(A1,{"[一-龟]+"})提取汉字。 详见下面链接的第4部分: [color=inherit !important]①WPS新增的REGEXP函数,非常好用!强烈推荐​mp.weixin.qq.com/s?__biz=MzIxOTYwNTA1OQ==&mid=2247503830&idx=1&sn=e2da716fbb69db0321965e0e6c921875&chksm=97da3efaa0adb7ecd1f8869d00232b9c93b09ca34e1b08eaa6be15a8354a9d3ac378a43a505c&scene=21#wechat_redirect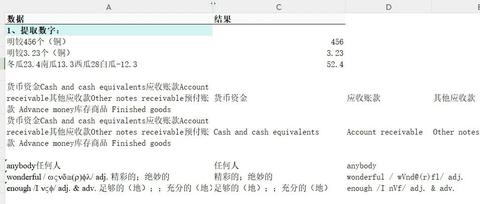
但当第二参数使用常量数组时,它只给出了每种情况的第一个值。 所以,可利用这个特点,来限定只提取第一个值: =REGEXP(A1,{"[一-龟]+"}) 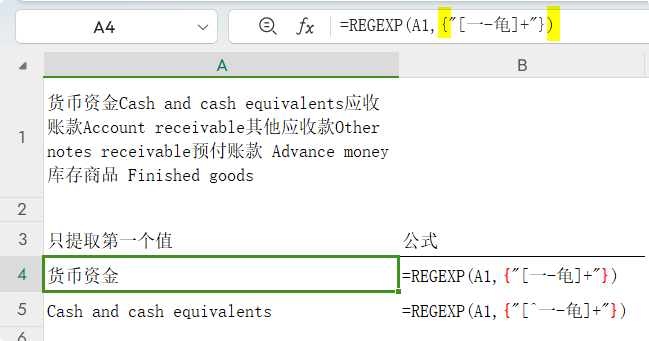
我们继续深入。 如果第二参数是单元格区域会怎么样呢?
 包含式反向查找(根据全称查简称) =TOCOL(REGEXP(F3,$C$3:$C$12,0),2) 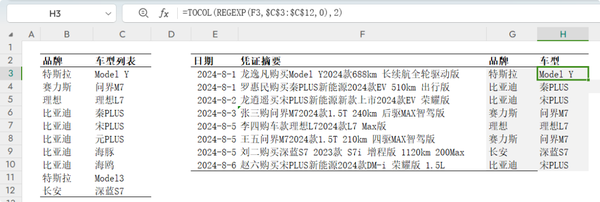
继续扩展,将摘要中购买的多个蔬菜和肉类名称提取出来合并: =TEXTJOIN("、",1,TOCOL(REGEXP(B2,$F$2:$F$10),2)) 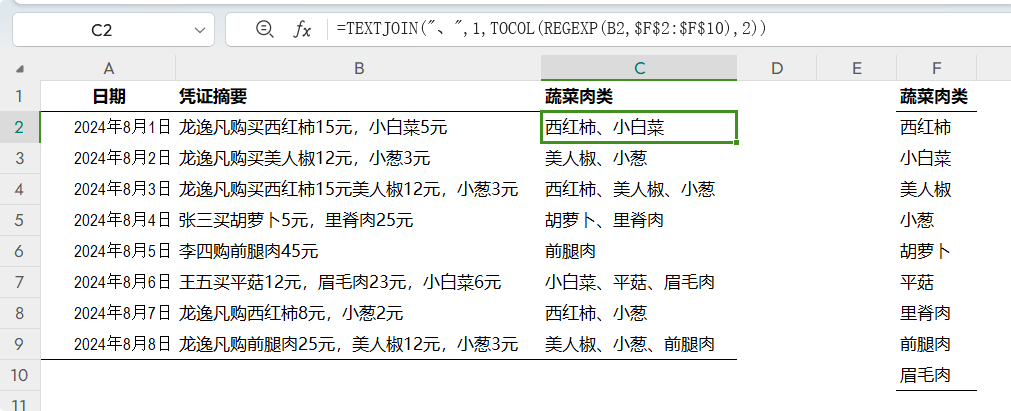
 根据不连续简称查全称 公式: =TOCOL(MAP($A$2:$A$9,LAMBDA(x,REGEXP(x,".*"®EXP(D2,"(.)",2,"\1.*")))),2) 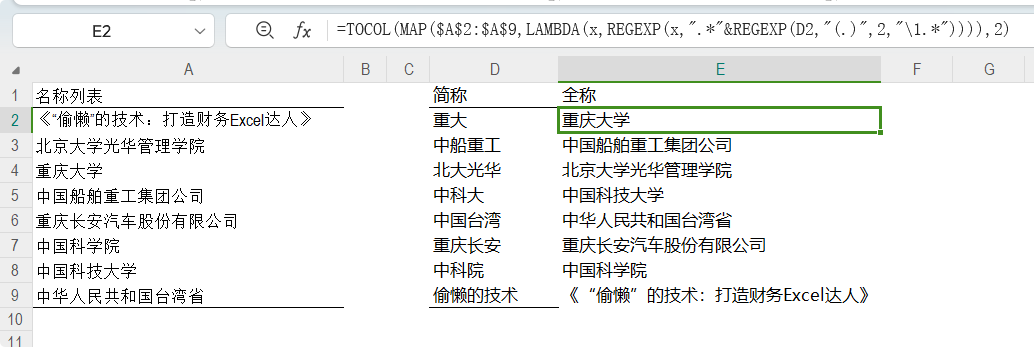
解释: 要理解这公式首先要理解用REGEXP提取每一个字符(拆分): 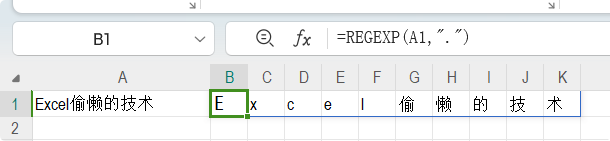
然后再用REGEXP的替换模式来插入。 具体用法见最里面的REGEXP函数: =REGEXP(D2,"(.)",2,"\1.*") 它是在每一个字之间插入“.*”,详细解释:(略) 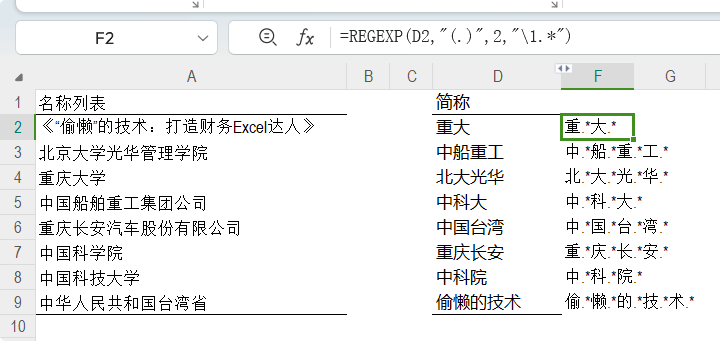
再在这个REGEXP函数的计算结果的前面,添加一个".*",将拼接结果做为最外围的REGEXP函数的第二参数的正则表达式。 由于REGEXP函数的第一参数不支持数组。所以得用MAP+LAMBDA函数,将A2:A9单元格区域的单元格,逐个传递给REGEXP的第一参数。 然后用TOCOL过滤掉计算结果中的错误值。
 给银行卡每四位添加一空格 从后往前每4位添加一空格的公式: =REGEXP(A45,"(?=(?:\d{4})+$)",2," ") 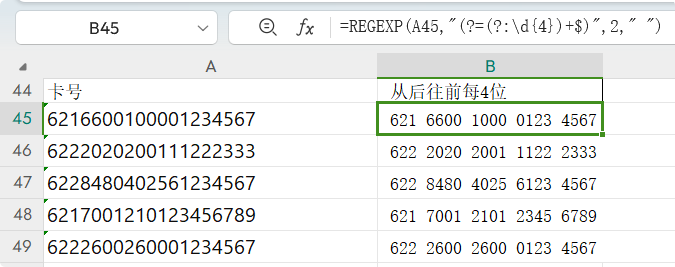
正则表达式解释:(略) 从前往后每4位添加一空格的公式 =REGEXP(A45,"(\d{4})(?=\d)",2,"\1 ") 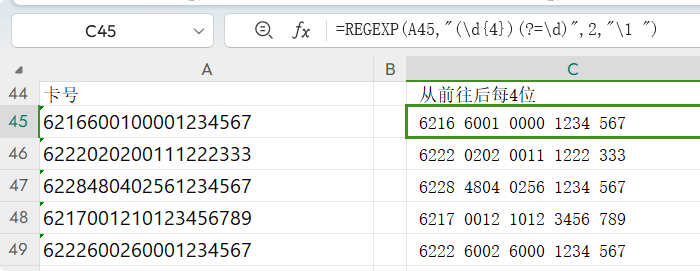
 给字符串中的数字添加千位分隔符 如果是数值,我们可以用TEXT函数来格式化,添加千位分隔符 公式: =TEXT(B6,"#,##0.00元") 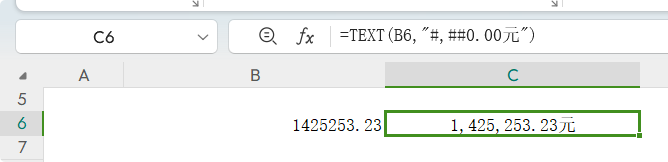
如果是文本中的数字,就不能使用TEXT函数了,可以用REGEXP函数来添加千位分隔符,公式: =REGEXP(B2,"(?<=\d)(?=(?:\d{3})+($|[^\d年]))",2,",") 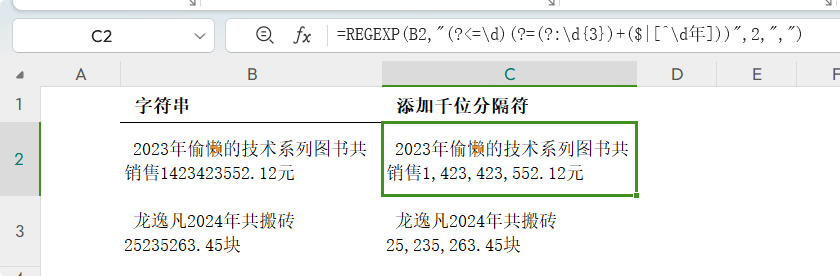
看了上面的内容,是不是觉得REGEXP函数很神奇。 你还发现了哪些神奇的用法,欢迎留言
|  沪公网安备 31011702000001号 沪ICP备11019229号-2
沪公网安备 31011702000001号 沪ICP备11019229号-2

 发表于 2024-5-27 14:41
发表于 2024-5-27 14:41
 发表于 2024-5-28 21:44
发表于 2024-5-28 21:44
 感谢分享
感谢分享 楼主
楼主