本帖最后由 龙逸凡 于 2024-5-28 14:22 编辑
上一篇我们介绍了正则表达式的基础知识、REGEXP函数的提取和拆分的基础入法。 今天我们继续:
 按多个指定字符拆分 公式: =REGEXP(A2,"[^*/-]+") 
正则表达式解释: - 由于EH对帖子长度有限制,现将正则表达式的解释删除,
 取指定第几节 在上面的公式外套一个INDEX函数,取指定的第几节 公式: =INDEX(REGEXP(A2,"[^*/-]+"),3) 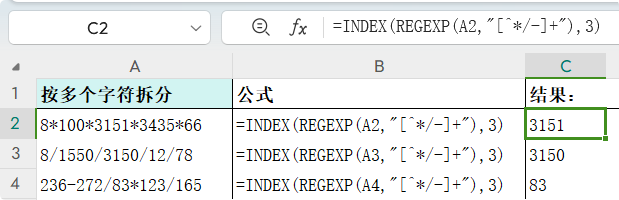
 提取多个指定字符前后的内容 提取“镇、乡、街道”之前(含)的内容 公式: =REGEXP(A2,"(.+)[镇乡街道]") 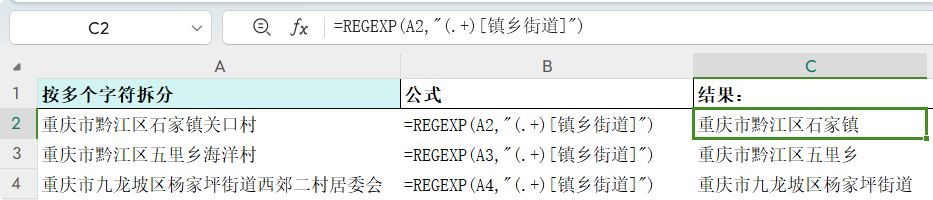
提取“镇、乡、街道”之后(不含)的内容 公式: =REGEXP(A2,"([^镇乡(街道)]+)$") 
 提取最后一个指定字符之前的内容(不含) 公式: =REGEXP(A2,"^.*(?=\\)") 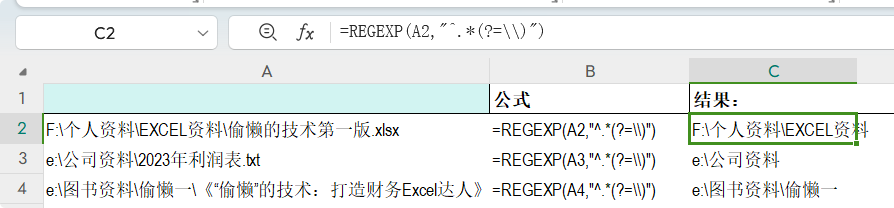
 使用REGEXP函数进行替换 公式 =REGEXP(A2,"(偷懒1)|(toulan3)|(偷lan2)",2," ") 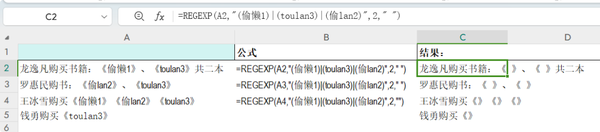
“|”是或的意思,三个分组之间用 | 分隔,表示逻辑“或”。这意味着只要单元格 A2 的内容匹配这三个子模式中的任意一个,正则表达式就会返回匹配成功。 REGEXP的第三参数为2表示进行替换。第三参数为替换后的内容。
 使用REGEXP函数进行插入 公式: =REGEXP(A2,"([一-龟]+)(\d{2})(.+)$",2,"\1\2偷懒\3") 
另外,再来看群友分享的一个插入案例,一个很牛的正则表达式,值得好好揣摩: 在二个字的姓名中插入空格 公式: =REGEXP(A2,"(?<=^|\+)([一-龟])([一-龟])(?=\+|/|$)",2,"\1 \2")

 去掉带汉字的括号内的内容、中括号内的所有内容 这是RPA群群友的问题,去掉带汉字的括号内的内容、中括号内的所有内容 
公式: =REGEXP(A2,"([(\(][^()]*[一-龟]+[^()]*[\))])|(【.*?】)",2,"") 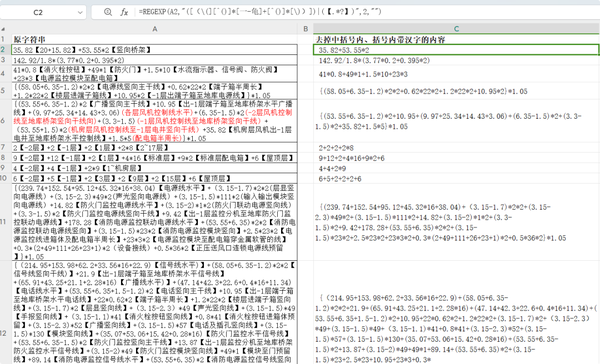
替换模式:""在这个例子中,替换模式是一个空字符串 "",这意味着如果找到匹配项,它将被替换为一个空字符串,即删除匹配到的内容。 如果要求和,还要使用substituts函数替换将中括号、大括号替换为小括号,然后再用EVALUATE函数求和(Excel只能在定义名称中使用) 完整公式 =EVALUATE(SUBSTITUTES(REGEXP(A2,"([(\(][^()]*[一-龟]+[^()]*[\))])|(【.*?】)",2,""),{"{","[","(","}","]",")"},{"(","(","(",")",")",")"})) 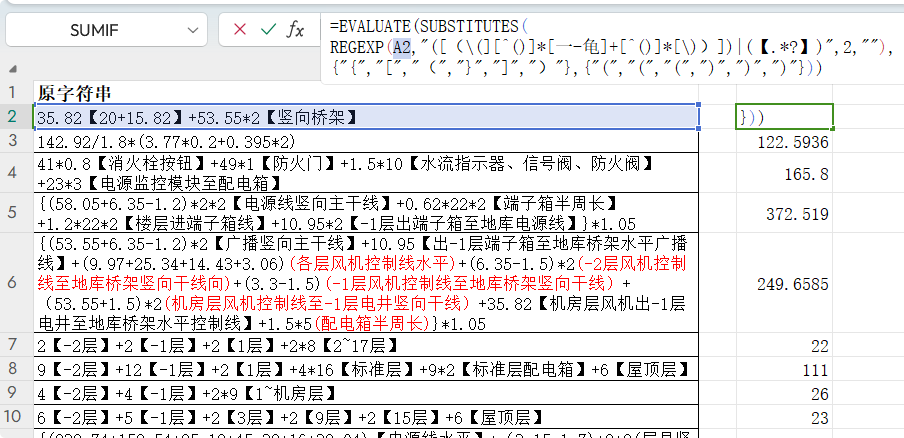
 提取整理个人信息 个人信息姓名在最前面,其他信息顺序不一致,且分隔符不一致。要用公式提取比较麻烦,用正则表达式来提取却得心应手。 
公式: =REGEXP(A2,"(^[一-龟]+)") =REGEXP(A2,"([0-9]{11})") =REGEXP(A2,"([一-龟]{5,})") =--REGEXP(A2,"(\d{4}年\d{1,2}月\d{1,2}日|\d{4}-\d{1,2}-\d{1,2})") =REGEXP(A2,"(?<=[^一-龟\w])([一-龟]\w+)")
这是REGEXP函数的第二篇,后面还有一篇,欢迎阅读
|  沪公网安备 31011702000001号 沪ICP备11019229号-2
沪公网安备 31011702000001号 沪ICP备11019229号-2

 发表于 2024-5-27 14:31
发表于 2024-5-27 14:31

 楼主
楼主 发表于 2024-5-28 21:45
发表于 2024-5-28 21:45
