|
|
[广告] Excel易用宝 - 提升Excel的操作效率 · Excel / WPS表格插件 ★ 免费下载 ★ ★ 使用帮助★
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
错误写法
凡用过正则表达式的表亲都知道,英文句号“.”,可匹配除换行符之外的所有字符。
比如:
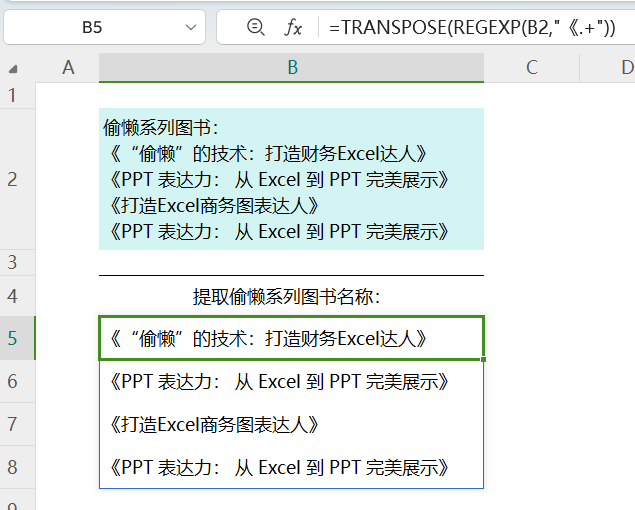
提取B2单元格中偷懒系列所有图书名称,只需提取左书名号及后面的所有字符即可(不含换行符)。
公式:
=TRANSPOSE(REGEXP(B2, "《.+"))
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
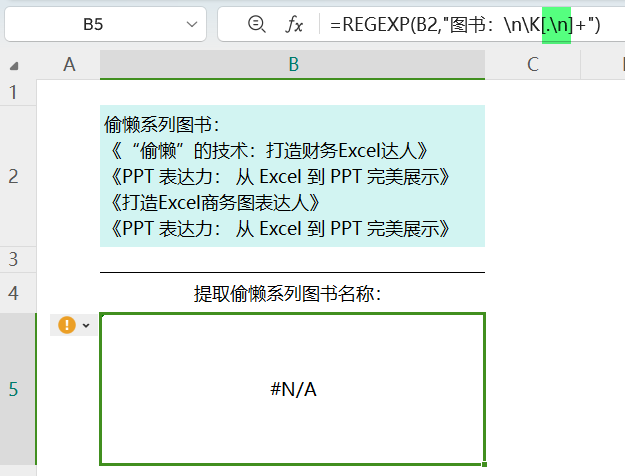
那如果要提取含换行符在内的所有字符呢?
也就是将“偷懒系列图书:"后面各图书名称及换行符提取到同一个单元格。
so easy!用英文句号.和\n不就是了
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
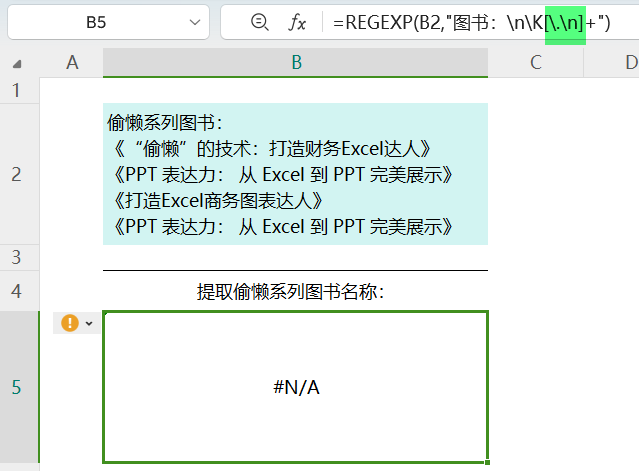
啊哦,出错了,正则表达式没写对。
想起来了,在字符组中,"."会失去特异功能,它变成普通字符了,看来得在前面加个转义符,恢复它的能力。
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
还是不正确!
那该用什么呢?
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
三种常用写法
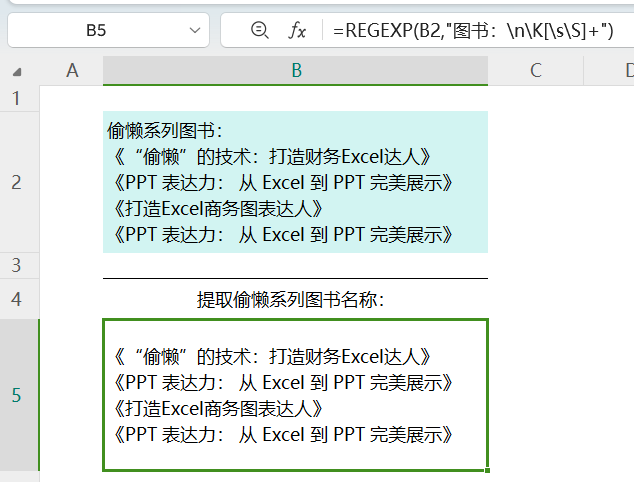
一般的正则表达式教程,会告诉我们:匹配含换行符在内的所有字符,有三种写法
[\s\S][\d\D][\w\W]
来试试看,
公式:
=REGEXP(B2,"图书:\n\K[\s\S]+")
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
公式解释:
匹配字符串 "图书:" 后跟一个换行符 \n。
专业的解释是:\K表示“重置匹配起点”。 \K 之前的内容会参与匹配,但不会出现在最终的匹配结果中。
用通俗地说话就是:你可以将\K理解为一般大砍刀,将它之前匹配到的内容一刀砍掉丢弃,不保留在匹配结果中。
详细解释及更多应用案例,请点击阅读以前的文章:
正则表达式的这些元字符,你顶多会两个,第一个很有用
匹配一个或多个任意字符,包括空白字符和非空白字符。[\s\S] 是一个字符组,匹配所有可能的字符。
说明:
此处的空白字符是正则表达式中的\s,不仅仅指空格,还包含换行符、回车符、制表符、换页符等。
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
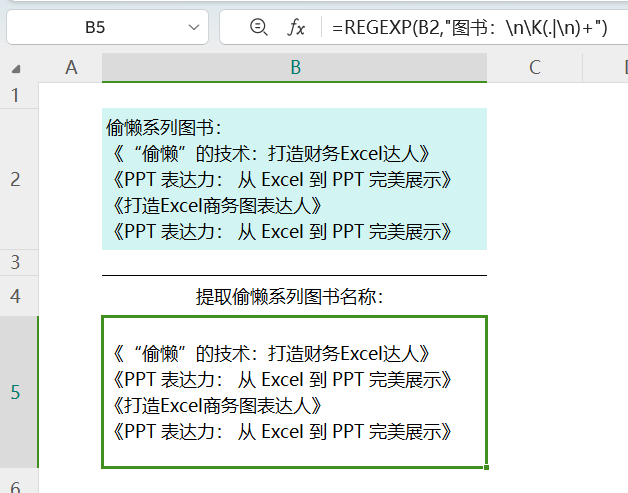
使用多选分支
使用竖线|,多选分支
公式:
=REGEXP(B2,"图书:\n\K(.|\n)+")
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
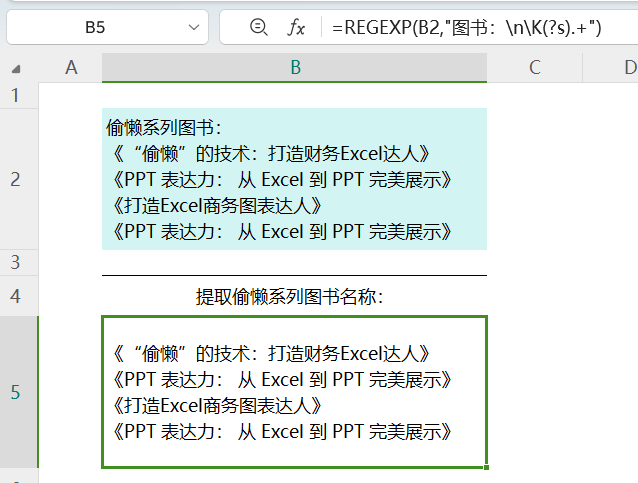
启用单行模式
用(?s)启用单行模式
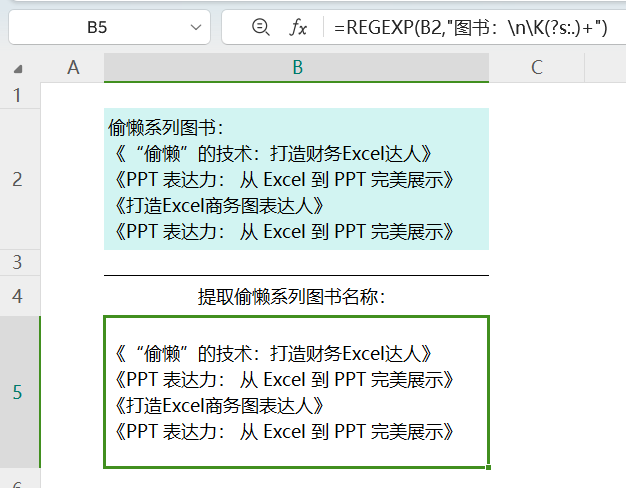
=REGEXP(B2,"图书:\n\K(?s).+")
助记:
s:single-line
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
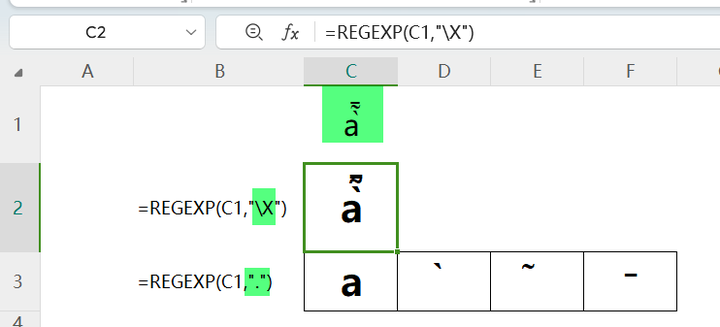
使用\X
\X 的作用是将一系列普通字符及后面的组合字符视为一个整体进行匹配,适合用于处理变音符、重音符等需要组合的字符。
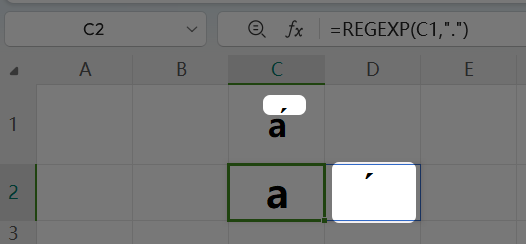
比如,á看起来是一个字符,实际上它是两个字符(两个Unicode代码点)
á=a+́
用.提取一下就可让它显露原形
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
以前写过文章介绍如何给汉字加圈,用的就是组合字符
详见:
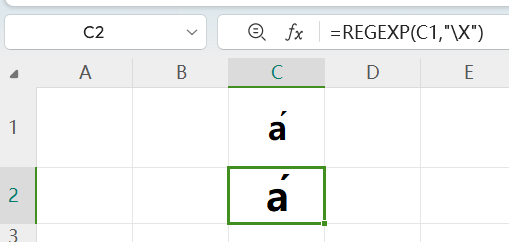
\X会将普通字符及后面的若干个组合字符视为一体,而不会象英文句号“.”棒打鸳鸯硬生生将合为一体的字符拆成独立的个体。
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
上面的内容不是本文要利用的。
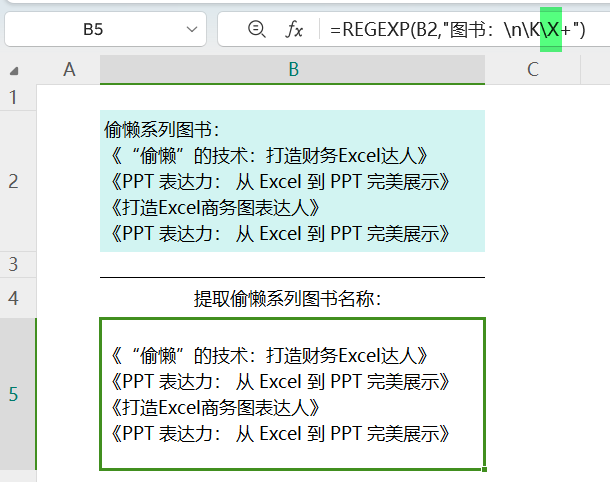
我们要利用\X的一点是:
\X会将换行符一视同仁,也就是说,一般情况下,可用它来近似代替:
[\s\S]
[\d\D]
[\w\W]
来看看效果:
=REGEXP(B2,"图书:\n\K\X+")
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
还有没有其他方法呢?
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
使用\C
\C本来的作用是按字节匹配。
我们如果用过len、lenb函数,就知道一个汉字是两个字节。在表格中,正则表达式并不用也不能按字节匹配,但它还是有点用处。
经龙逸凡测试,它能起到匹配所有字符的作用。
公式:
=REGEXP(B2,"图书:\n\K\C+")
 [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)] [backcolor=rgba(0, 0, 0, 0.1)]
[backcolor=rgba(0, 0, 0, 0.1)]
添加图片注释,不超过 140 字(可选)
各位表哥表妹,你还知道其他写法吗?
本文系龙逸凡学习正则表达式元字符的一些摸索心得,文中\C\X的用法,纯属旁门左道,不一定正确,如有错误之处,欢迎留言指正。
|
评分
-
1
查看全部评分
-
|
 沪公网安备 31011702000001号 沪ICP备11019229号-2
沪公网安备 31011702000001号 沪ICP备11019229号-2

 发表于 2024-12-23 23:40
发表于 2024-12-23 23:40