|
举例 在data.xlsx中有一数据表,在字段 Header1 中存储了一些索引号,但这个索引号可能有重复值,就像下图中红框所示有两个 101,初始表格如下: 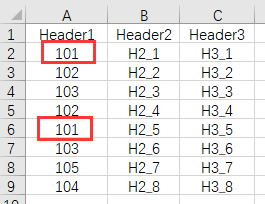
另一个文件target.xlsx中有如下一些数据:
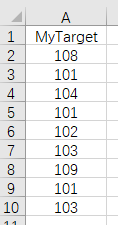
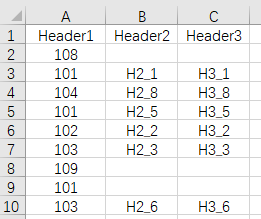
现在要求将data.xlsx中的数据按照MyTarget的顺序排列,其中第1个101表示 Header1 为101的第1条记录,第2个101则为第2条记录,第3个101找不到第3条记录,则为空行。最终结果如下图所示:
编写SPL脚本: | A | | 1 | =T("e:/work/data.xlsx").derive(key) | | 2 | =T("e:/work/target.xlsx").derive(key) | | 3 | =A1.group(Header1).run(~.run(key=Header1/"_"/#)) | | 4 | =A2.group(MyTarget).run(~.run(key=MyTarget/"_"/#)) | | 5 | =A1.align(A2:key,key) | | 6 | =A5.new(A2(#).MyTarget:Header1,~.Header2,~.Header3) | | 7 | =T("e:/work/data2.xlsx",A6) |
A1 读出data.xlsx数据并新增一列key,用于生成要用来对齐的键值 A2 读出target.xlsx数据并新增一列key,用于生成要用来对齐的键值 A3 将A1按Header1分组,循环每一组,再循环组中每条记录,让key的值为Header1加下划线再加它在组中的序号 A4 与A3同理 A5 让A1中的key按照A2中的key的顺序对齐 A6 用A5构造新的数据集,用A2中对应行号#的MyTarget值为新列Header1的值,再取出原A5中的Header2和Header3 A7 把A6中的结果保存到文件data2.xlsx
|  沪公网安备 31011702000001号 沪ICP备11019229号-2
沪公网安备 31011702000001号 沪ICP备11019229号-2


 发表于 2022-3-18 10:00
发表于 2022-3-18 10:00
