|
|
[广告] Excel易用宝 - 提升Excel的操作效率 · Excel / WPS表格插件 ★ 免费下载 ★ ★ 使用帮助★
本帖最后由 雷公子 于 2018-8-18 23:33 编辑
来混个脸熟顺便分享篇自己整理的内容
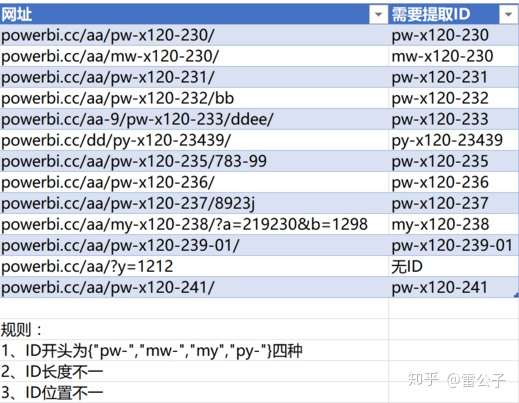
需要解决的问题:
我们提取网址中的页面ID,页面ID在任意两个"/"之间,但是位置不固定,前后字符不固定,长度不固定,唯一的特征是开头是{“pw-”,“py-”,“my-”,“mw-”}
解决方法1 正则表达式1(效率一般)使用M语言+正则表达式的方式提取 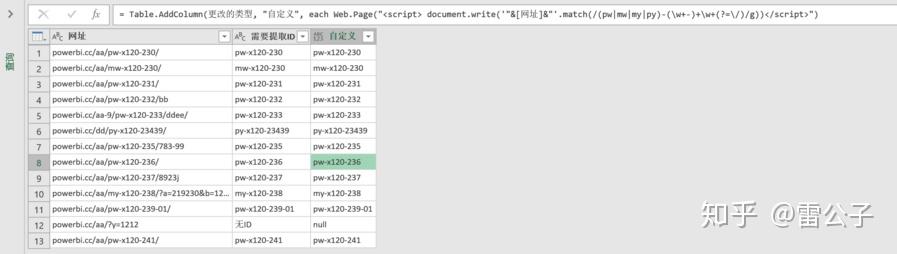 Web.Page("<script> document.write('"&[网址]&"'.match(/(pw|mw|my|py)-(\w+-)+\w+(?=\/)/g))</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0} Web.Page("<script> document.write('"&[网址]&"'.match(/(pw|mw|my|py)-(\w+-)+\w+(?=\/)/g))</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}
方法2 正则表达式2(效率一般)Web.Page("<script> document.write('"&[网址]&"'.match(/([pm][wy])-[^/]*/g))</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}
方法3List.RemoveNulls( List.Transform( {"pw-","mw-","my","py-"}, (x)=>[a=Text.BetweenDelimiters([网址],x,"/"),b=if a<>"" then x&a else null] ) ){0}?
方法4 目前测试效率最高List.RemoveNulls( List.TransformMany( Text.Split([网址],"/"), each {"py","pw","my","mw"}, (x,y) => if Text.StartsWith(x,y) then x else null ) ){0}?
List.Max( List.TransformMany( Text.Split([网址],"/"), each {"py","pw","my","mw"}, (x,y) => if Text.StartsWith(x,y) then x else null ) )
方法5List.Mode( Text.Split([网址],"/")&{"py","pw","my","mw"," "},(x)=>Text.Start(x,2))
方法6 效率与方法4相当List.Accumulate( Text.Split([网址],"/"), "", (x,y)=>x&(if List.Contains({"py","pw","my","mw"},y,(a,b)=>Text.StartsWith(b,a)) then y else ""))
特别说明:以上方法来自群讨论各位大神的方法,有需要的小伙伴可以自行学习
|
评分
-
3
查看全部评分
-
|
 沪公网安备 31011702000001号 沪ICP备11019229号-2
沪公网安备 31011702000001号 沪ICP备11019229号-2

 发表于 2018-8-18 23:30
发表于 2018-8-18 23:30